
特征交叉 | 从曾将的王者LR开始

LR是曾经的王者,理解好该方法对理解特征交叉其它方法基础且重要。
目录
- 1 特征交叉概览
- 1.1 特征和特征交叉的重要性
- 1.2 特征交叉方法概览
- 2 LR
- 2.1 logistic分布
- 2.2 LR模型
- 2.3 LR模型参数估计
- 2.4 LR被广泛使用的原因
- 2.5 LR中的特征交叉
- 相关面试问题
1 特征和特征交叉的重要性
机器学习领域,模型的学习过程是从数据中挖掘信息的过程。模型可用的数据,是通过特征表达的,特征是模型可挖掘的信息的载体,因此特征是影响模型能挖掘到什么信息的最根本因素,这也是特征工程在推荐领域前深度学习时代被各大厂重视的原因,如果从源头上特征就没有设计好,那模型能挖掘到的信息的上限就被限制住了。
随着深度学习在推荐领域的广泛使用,特征工程的重要性不再像前深度学习时代那样被广泛提及,这与DNN对特征提取和函数拟合的有效性被高估有关。DNN可以提取特征之间的高阶交互信息,可以拟合任何函数,但这些都是理论上可以实现,具体效果依然受限于给DNN的数据特征,受限于网络结构,所以想要让DNN发挥它特征提取的特长,依然需要花心思设计特征和网络结构,使其和当前场景更贴合。
各个特征表面上看是相互独立的,但特征和特征之间存在一些关联模式,比如<女性,瑜伽>,<男性,篮球>,在性别和运动类型这两个特征上,女性和瑜伽会经常同时出现,而男性则往往和篮球同时出现,因此在特征设计上考虑特征之间的关联性,可以给模型提供更好的特征输入。
DNN通过激活函数和全连接实现了特征之间的高阶交互,而这种交互是隐式的,无法使用显式的表达式表示,我们无法知道通过DNN交叉后的高阶特征具体是如何构成的,因此需要通过显式方式,让特征之间进行可知的交叉。显式的方式包括手工设计交叉特征和设计网络结构使模型进行显式特征交叉。
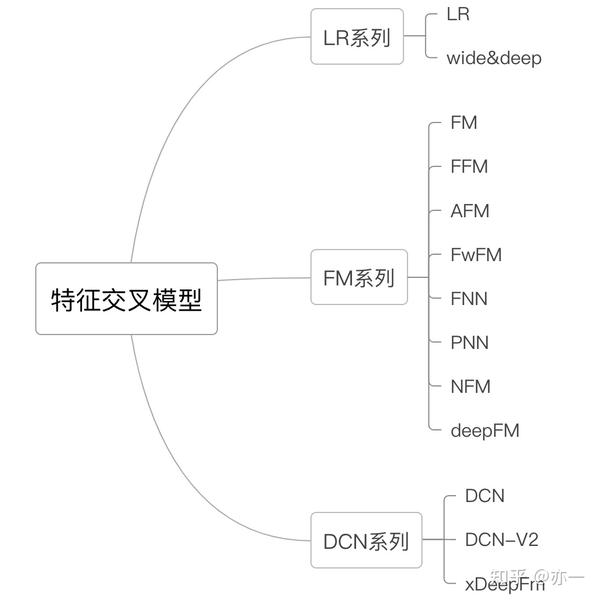
特征交叉的方法比较多,会分若干篇讲,主要归为几类,如图1所示:(1) 以LR为基础的系列,(2) 以FM为基础的系列,(3) 以DCN为基础的系列。另外attention这条分支之后也会分享。LR系列方法使用的是手工设计交叉特征,FM、DCN系列则是通过设计网络结构实现显式特征交叉。
从模型结构的角度看,以LR为基础的系列方法没有涉及特征交叉,但它是推荐领域在前深度学习时代被使用最广泛的模型,同时后续提出的各种对特征交叉进行改进的模型结构,基本上是基于LR系列模型的缺点而产生的,另外,在使用LR的时候,通常配合手动特征交叉,即人工设计交叉特征后将其作为一个特征项放入LR中,因此把LR系列的模型结构也放在这个主题里进行分享。

2 LR
LR全称为逻辑斯蒂回归(logistic regression),虽然名字里带有“回归”两个字,但它是一个分类方法。LR假设数据服从logistic分布,再利用极大似然估计法估计模型参数,从而得到LR模型。
2.1 logistic分布
logsitic分布是连续概率分布,分布函数和密度函数分别为式子(1)和式子(2),其中 \mu 为位置参数, \gamma 为形状参数,即如图2所示,\mu决定了函数所在的位置,\gamma决定了函数构成的曲线的形状,\gamma值越小,曲线在中心附近增长越快。当 \mu=0 , \gamma=1 时,logistic分布函数则变成深度学习中常用的sigmoid函数。
F(x)=P(X \leq x) = \frac{1}{1+e^{-(x-\mu)/\gamma}} \tag{1}
f(x) = F^{\prime}(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^{2}} \tag{2}


2.2 LR模型
LR模型既可以用于二分类,也可以用于多分类,二分类和多分类的原理和求解方式类似。本文详细介绍二分类,再简单介绍多分类。
对随机变量 X ,用条件概率 P(Y|X) 表示logistic分布,随机变量 X \in R^n , Y\in {\{0, 1\}} 。若 x 为样本空间里的某个输入,LR模型则可表示为如式子(3)所示的条件概率分布,其中 w \in R^n 和 b \in R 是参数, w 称为权值向量, b 为偏置。
P(Y=1 | x) = \frac{e^{w\cdot x +b}}{1+e^{w\cdot x +b}} \\ P(Y=0 | x) = \frac{1}{1+e^{w\cdot x +b}} \\ \tag{3}
为了方便,对 w 和 x 进行扩充,即 w=(w^{(1)}, w^{(2)},...,w^{(n)}, b)^\mathrm{T} , x=(x^{(1)}, x^{(2)},...,x^{(n)}, 1)^\mathrm{T} ,则LR模型可以表示为式子(4)。
P(Y=1 | x) = \frac{e^{w\cdot x}}{1+e^{w\cdot x}} \\ P(Y=0 | x) = \frac{1}{1+e^{w\cdot x}} \\ \tag{4}几率的定义为一个时间发生的概率和不发生概率的比值。LR模型的对数几率可以表示为式子(5),可以看出,LR的对数几率是输入 x 的线性函数。线性函数值越接近正无穷,概率值越接近1,反之线性函数值越接近负无穷,概率值越接近0。
log\frac{P(Y=1|x)}{P(Y=0|x)} = w \cdot x \tag{5}2.3 LR模型参数估计
模型参数估计即求解w的过程,使用的是极大似然估计法。用 p(x) 表示输出为1的条件概率,即 P(Y=1|x)=p(x) ,则 P(Y=0|x) = 1-p(x) ,似然函数如式子(6)所示,其中N为样本数量, x_i 为第i个样本的输入, y_i 为第i个样本的输出。
\prod_{i=1}^{N}(p(x_i))^{y_i}(1-p(x_i))^{1-y_i} \tag{6}
对似然函数求对数可表示为式子(7)。
L(w) = \sum_{i=1}^{N}{(y_ilogp(x_i)+(1-y_i)log(1-p(x_i)))}\tag{7}
极大似然等价于极大对数似然,即对 L(w) 求极大值,可采用梯度下降或者拟牛顿法进行求解。若 w 的极大似然估计为 \hat{w} ,则学到的LR模型可表示为式子(8)。
P(Y=1 | x) = \frac{e^{\hat{w}\cdot x}}{1+e^{\hat{w}\cdot x}} \\ P(Y=0 | x) = \frac{1}{1+e^{\hat{w}\cdot x}} \\ \tag{8}
多分类的LR模型类似二分类。假设Y的取值集合为 \{1,2,3,...,K\} ,则LR模型可表示为式子(9),其中 x \in R^{n+1} , w_i \in R^{n+1} ,求解过程也类似二分类,使用极大似然估计对模型参数进行估计。
P(Y=k | x) = \frac{e^{w_k\cdot x}}{1+\sum_{i=i}^{i=K-1}{e^{w_i\cdot x}}} , k=1,2,...,K-1\\ P(Y=K | x) = \frac{1}{1+\sum_{i=i}^{i=K-1}{e^{w_i\cdot x}}} \\ \tag{9}2.4 LR被被广泛使用的原因
LR在业界被广泛使用,主要是因为它的简单性、并行性和可解释性。
简单性
模型原理简单,需要的参数少,结构简单。
并行性
在模型求解过程中,可以进行并行化。
在用梯度下降或者拟牛顿法对模型求解时,主要做的是梯度的计算,常用的LR求解方法在计算梯度时,只需要进行向量的点乘和相加,因此可以将每个迭代过程拆成相互独立的计算步骤,由不同的节点独立运算,最后再归并计算结果,因此求解过程可以并行,在工程上可以提高效率。
可解释性
具体分析可在公众号【播播笔记】回复”LR“获取。
2.5 LR中的特征交叉
LR中的特征交叉分析以及优缺点,可在公众号【播播笔记】回复”LR“获取。
相关面试问题
- LR优缺点
- LR使用时需要注意什么
本文提到了一些相关知识点,比如损失函数,优化器等,后续有时间也会陆续分享。
推荐系列文章:
推荐基础知识点
工具
工作相关的内容会同步在”播播笔记“这个公众号更新
生活的思考和记录会更新在”吾之“这个公众号
